- Published on
Une micro VM et un assembleur en 1000 lignes de C++
- Authors
- Name
- Anthony Rabine
Lors d'un précédent article, nous avions fait le tour des solutions de scripting embarquées. Pour notre projet de boîte à histoires, il a été décidé d'utiliser une machine virtuelle très simple et flexible qui se chargera de dérouler le conte et ses embranchements. La solution présentée ici s'avère être un très générique exécuteur de script.
Le CPU et la machine
Il faut tout d'abord tracer les limites de ce que l'on va modéliser ; ici nous souhaitons créer un CPU virtuel avant toute chose. De cette façonn, nous pourrons utiliser ce composant dans différentes machines virtuelles. Une machine,c'est un CPU avec des périphériques autour (entrées/sorties clavier, son, écran, réseau etc.).
Notre CPU aura donc un certain nombre d'instructions, à définir mais on veut les limiter le plus possible et une ouverture vers plus de modularité via un appel système. Cet appel système sera une instruction CPU spécifique et à l'aide des argruments passés dans des registres, il sera possible d'étendre les possibilités en communicant avec la machine justement.
Avoir un jeu d'instruction limité signifie qu'il faudra plus d'instructions pour réaliser une tâche ou un calcul : c'est le compromis à avoir et ce n'est pas simple. Plus d'instruction veut dire aussi plus de lenteur d'exécution.
Le modèle de programmation et mémoire
On définit par modèle de programmation l'ensemble des éléments mis à disposition du programmeur pour réaliser des boucles, des calculs, des tests, des embranchements.
Les instructions
Les instructions font parti de ce modèle mais pas seulement : il faut définir des cases mémoires pour que le CPU puisse travailler. Sur ce point, il existe deux grand modèles, RISC et CISC, nous choisissons un modèle de type RISC qui va limiter le nombre d'instructions (et donc la complexité de notre VM, le nombre de lignes), bien que ce ne soit pas le format le plus judicieux pour une VM visant la rapidité. Dans le cas de recherche de performance pure de VM, il vaut mieux multiplier le nombre instructions.
Les registres
Les registres sont l'intermédiaire entre le code et la mémoire, en quelque sorte des mémoires tampon, pour effectuer un calcul par exemple. Si on souhaite incrémenter une variable, la tâche sera :
- Copier la variable depuis la RAM vers un registre libre
- Incrémenter la valeur dans ce registre
- Recopier cette valeur à son emplacement en RAM
De part le nombre réduit d'instructions le principal travail sera d'effectuer des load et store entre la mémoire RAM et les registres.
Dans notre cas, nous allons définir les éléments suivants :
| name | number | type | call-preserved |
|---|---|---|---|
| r0-r9 | 0-9 | general-purpose | N |
| t0-t9 | 10-19 | temporary registers | Y |
| pc | 20 | program counter | Y |
| sp | 21 | stack pointer | Y |
| ra | 22 | return address | N |
On prend large : dix registres de travail, dix autres temporaires et on se fixe une règle d'appel : si du code doit être généré, quels registres doivent être préservés par l'appelant et l'appelé. Dans notre cas, les registres préservés devront donc être sauvegardés par la fonction appelée (la fonction appelante doit retrouver le même contexte au retour de la fonction). "call-preserved" est synonyme de "callee saved" en anaglais.
Les registres génériques seront utilisés pour passer les arguments à une fonction et pour y stocker les éventuels variables de retour.
Les autres registres spéciaux sont classiques pour le bon déroulement de l'exécution d'un programme : le pointeur de code qui indique la prochaine instruction à exécuter, le pointeur de la stack et le stockage de l'adresse de retour. Tous les registres sont contigüs en mémoire.
La mémoire
Autre choix à préciser sur le modèle mémoire entre les deux grands principes :
- Von Neuman : le plan mémoire entre la ROM et la RAM est unifié (entre 0x0000 et 0xFFFF par exemple)
- Harvard : ROM et la RAM ne sont pas dans le même plan mémoire (chacune commence à l'adresse 0x0000 par exemple)
Notre VM n'a aucun intérêt à utiliser l'architecture Harvard à part complexifier le mécanisme, donc on va partir sur la première solution.
Création des instructions
Maintenant que le modèle de programmation est connu, nous allons créer les instructions. Mon but est de limiter au maximum le nombre d'instruction, on va rester dans le simple. Il est possible de n'utiliser à l'extrême qu'une seule instruction, le MOV par exemple, au détriment de la taille de code pour exécuter une fonction simple comme un calcul ou un appel.
Chaque instruction est codée sur un octet. Les arguments à l'instruction sont insérées à la suite, dès lors chaque instruction a une taille variable en ROM. Les exemples présentés dans le tableau correspondent à l'assembleur qui sera utilisé, nous y reviendrons dans le prochain chapitre.
| Instruction | Encoding | Arguments (bytes) | Description | Example |
|---|---|---|---|---|
| nop | 0 | 0 | Do nothing | |
| halt | 1 | 0 | Halt execution | |
| syscall | 2 | 1 | System call handled by user-registered function. Machine specific. Argument is the system call number, allowing up to 256 system calls. | syscall 42 |
| lcons | 3 | 4 | Store an immediate value in a register. Can also store a variable address. | lcons r0, 0xA201d800, lcons r2, $DataInRam |
| mov | 4 | 2 | Copy a register in another one. | mov r0, r2 |
| push | 5 | 1 | Push a register onto the stack. | push r0 |
| pop | 6 | 1 | Pop the first element of the stack to a register. | pop r7 |
| store | 7 | 3 | Copy a value from a register to a ram address located in a register with a specified size | store @r4, r1, 2 ; Copy R1 to address of R4, 2 bytes |
| load | 8 | 3 | Copy a value from a ram address located in a register to a register, with a specific size. | load r0, @r3, 1 ; 1 byte |
| add | 9 | 2 | sum and store in first reg. | add r0, r2 |
| sub | 10 | 2 | subtract and store in first reg. | sub r0, r2 |
| mul | 11 | 2 | multiply and store in first reg . | mul r0, r2 |
| div | 12 | 2 | divide and store in first reg. | div r0, r2 |
| shiftl | 13 | 2 | logical shift left. | shl r0, r1 |
| shiftr | 14 | 2 | logical shift right. | shr r0, r1 |
| ishiftr | 15 | 2 | arithmetic shift right (for signed values). | ishr r0, r1 |
| and | 16 | 2 | and two registers and store result in the first one. | and r0, r1 |
| or | 17 | 2 | or two registers and store result in the first one. | or r0, r1 |
| xor | 18 | 2 | xor two registers and store result in the first one. | xor r0, r1 |
| not | 19 | 1 | not a register and store result. | not r0 |
| call | 20 | 1 | Set register RA to the next instruction and jump to subroutine, must be a label. | call .media |
| ret | 21 | 0 | return to the address of last callee (RA). | ret |
| jump | 22 | 1 | jump to address (can use label or address). | jump .my_label |
| jumpr | 23 | 1 | jump to address contained in a register. | jumpr t9 |
| skipz | 24 | 1 | skip next instruction if zero. | skipz r0 |
| skipnz | 25 | 1 | skip next instruction if not zero. | skipnz r2 |
On retrouve donc les grandes familles d'instructions :
- Les manipulations de regitres entre eux
- Les instructions système
- Les instructions pour travailler entre la mémoire RAM et les registres (dans les deux sens), load, store, push, pop
- Les instructions arithmétiques et logiques
- Les instructions de saut et d'embranchement conditionnels
Nous avons donc 26 instructions, ça va vite mine de rien parce que ces seules instructions vont nénanmoins nécessiter plusieurs lignes pour arriver à nos fins. Je pense notamment les instructions de saut conditionnel qui nécessiteront de préparer les registres avvant le saut (registre à zéro ou non).
Implémentation de la VM
La VM est en réalité très simple. Nous connaissans notre format binaire, chaque instruction est codée sur un octet avec des arguments ou non. Notre VM sera implémentée sous la forme d'un ... gros switch...case !
chip32_result_t chip32_step(chip32_ctx_t *ctx)
{
chip32_result_t result = VM_OK;
_CHECK_ROM_ADDR_VALID(ctx->registers[PC])
uint8_t instr = ctx->rom.mem[ctx->registers[PC]];
if (instr >= INSTRUCTION_COUNT)
return VM_ERR_UNKNOWN_OPCODE;
uint8_t bytes = OpCodes[instr].bytes;
_CHECK_BYTES_AVAIL(bytes);
switch (instr)
{
case OP_NOP:
{
break;
}
case OP_HALT:
{
return VM_FINISHED;
}
case OP_SYSCALL:
{
const uint8_t code = _NEXT_BYTE;
if (ctx->syscall != NULL)
{
if (ctx->syscall(ctx, code) != 0)
{
result = VM_WAIT_EVENT;
}
}
break;
}
// ...
}La fonction est à appeler dans une boucle, elle va décoder une seule instruction. De cette manière, nous pourrons l'appeler dans un code de débogage ligne par ligne. On commence par lire la mémoire ROM, on récupère l'instruction courante et on la décode dans le switch, le tout entouré de multiples protections à l'aide de macros.
La structure de contexte regroupe tous les éléments de notre CPU et des pointeurs vers notre zone de RAM et de ROM. L'avantage est que l'on peut faire pointer notre programme vers un élément en lecture seule, une vraie ROM Flash par exemple.
struct chip32_ctx_t
{
virtual_mem_t rom;
virtual_mem_t ram;
uint16_t stack_size;
uint32_t instrCount;
uint16_t prog_size;
uint32_t max_instr;
uint32_t registers[REGISTER_COUNT];
syscall_t syscall;
};Le code de la VM tient dans ... moins de 400 lignes de code C.
L'assembleur
Passons à l'assembleur. Nous allons fournir un langage sous forme textuelle afin de faciliter la conception de programmes en langage machine ainsi que le débogage.
Voici un petit exemple (c'est un extrait d'un code plus complet) :
jump .mediaEntry0004
$qui_sera_le_hero DC8 "qui_sera_le_hero.wav", 8
$mediaChoice0004 DC32, 2, .mediaEntry0005, .mediaEntry0003
$bird DC8 "bird.qoi", 8
$un_oiseau DC8 "un_oiseau.wav", 8
; ---------------------------- Base node Type: Transition
.mediaEntry0004:
lcons r0, $fairy
lcons r1, $la_fee_luminelle
syscall 1
lcons r0, .mediaEntry0006
retLe programme démarre de la première ligne tout en haut, les lignes vides ou avec un commentaire (caractère point virgule) sont passées. La première instruction sera donc de sauter vers le point d'entrée, une sorte de main(). Les labels commencent par un point, les instructions peuvent être indentées, c'est assez libre là dessus.
Un programme a besoin de déclarer deux types de variables :
- Des constantes, stockées en ROM
- Das variables, en RAM
Nous avons donc créé une petite grammaire pour déclarer des constantes ou des zones assez librement :
$yourLabel DC8 "a string", 5, 4, 8 ; Déclaration de constantes
$MaVar DV32 14 ; Variable en RAM : 14 emplacements de taille 32-bitsLa première colonne est le nom de la variable qui doit commencer par le caractère dollar. La deuxième colonne est le type de donnée : D pour Data, C pour Constant et V pour Volatile suivi de la taille de base. Dans le cas d'une constante, on peut aligner plusieurs variables séparées par des virgules, des entiers ou des chaînes de caractères. Pour la RAM, il suffit de déclarer une taille de base et d'une longueur (c'est toujours un tableau en gros).
Autant la VM est développée en C, pour être le plus facile à embarquer, autant l'assembleur est en C++ parcequ'on dispose alors de containeurs et des classes de la librairie standard qui sont bien utiles. L'assembleur compte moins de 500 lignes de code. Qui a dit que le C++ est verbeux ?
Voici le code quasi complet (il manque les headers) : software/chip32/chip32_assembler.cpp
Exemple d'intégration dans un éditeur graphique
Et la finalité dans tout ça ? Permettre d'ajouter une variabilité à un programme embarqué figé, par nature, comme le ferait l'interpréteur d'un langage de script. On peut imaginer l'utiliser pour contrôler des automatismes comme NodeRed.
Nous allons l'utiliser pour notre éditeur d'histoires avec un système de programmation graphique à base de noeuds. Voici ce que ça donne :
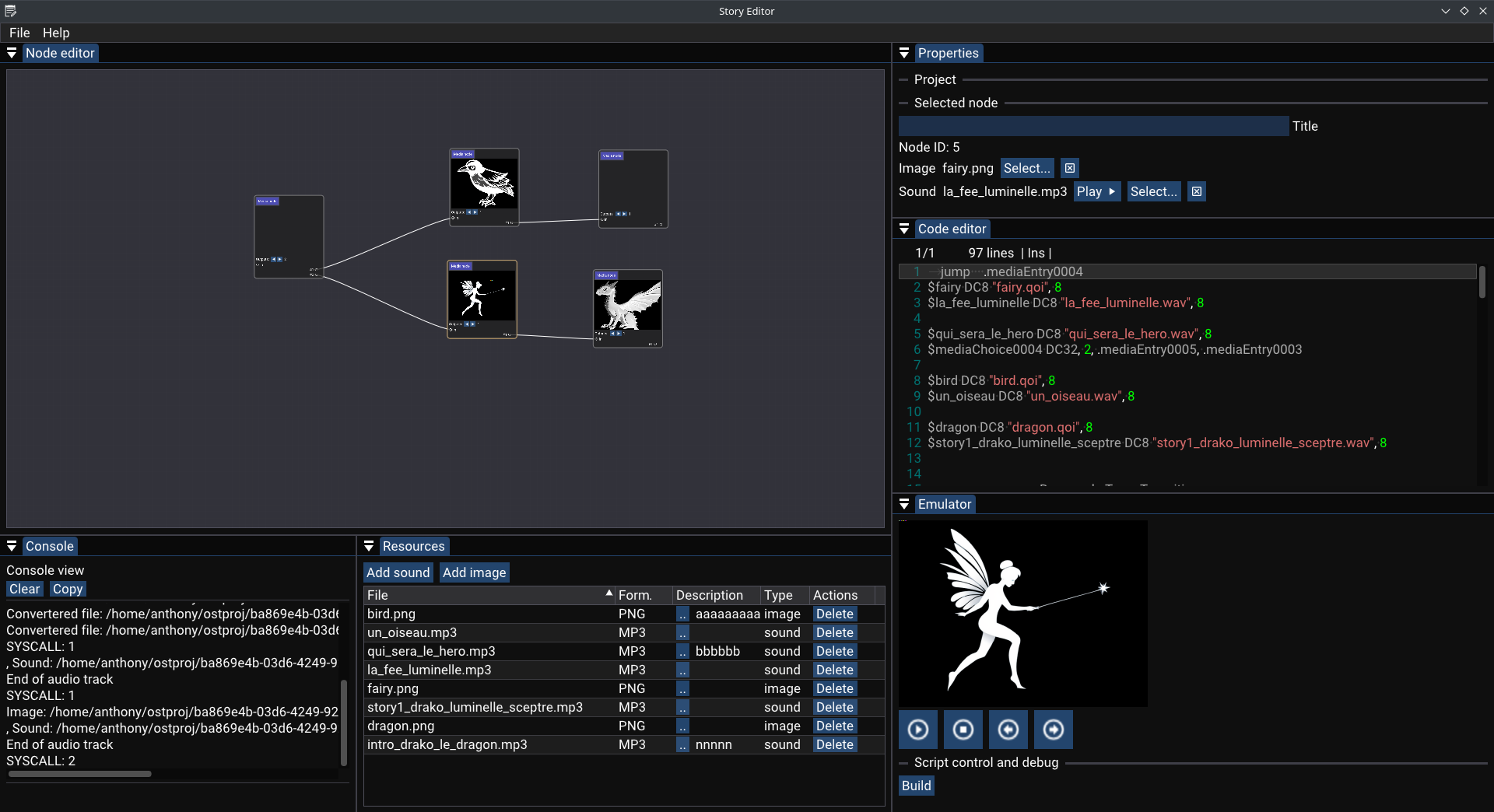
Chaque noeud génère son lot de code, un jump est effectué entre chaque noeud. Dans cet éditeur, au moment d'écrire cet article, seulement un noeud existe, un noeud assez complexe de type "media", capable d'afficher une image ou de jouer des sons (appels systèmes machine).